.svg)


In the field of cloud data management, Amazon Web Services (AWS) offers a variety of storage and analytics solutions. Two of the most important services in this area are Amazon Redshift and Amazon S3. For businesses using SAP data extraction tools (e.g. the Xtract tool suite from Theobald Software), understanding the nuances between these two AWS services is crucial. This blog post explores how Xtract Universal integrates with Amazon Redshift and S3, to help to choose the right destination for any SAP data needs.
Xtract Universal extraction types for SAP data: Integration with Amazon Redshift and S3
Xtract Universal supports the following ten extraction types to meet different SAP data extraction needs. Here is an overview of the components available for extracting data from SAP systems to either Amazon destination:
- BAPI accesses BAPIs and RFC function modules.
- BW Cube extracts data from SAP BW InfoCubes and BEx Queries.
- BW Hierarchy extracts Hierarchies from an SAP BW / BI system.
- DeltaQ extracts Data Sources (OLTP) and extractors from ERP and ECC systems.
- ODP extracts data via the SAP Operational Data Provisioning (ODP) framework for source objects including CDS Views, HANA Views, BW/4HANA objects, BW extractors, SLT server.
- Open Hub Services (OHS) extracts InfoSpokes and OHS destinations.
- Query extracts ERP queries. (SQ01 queries)
- Report extracts ABAP Reports (T-Codes).
- Table extracts data from SAP tables & views; allows joining several tables on the SAP side.
- TableCDC extracts change data from SAP tables.
By leveraging the Xtract Universal’s various components, SAP data can be effectively integrated with Amazon Redshift and S3, taking advantage of each platform’s strengths. Redshift provides high-performance analytics and rapid query capabilities, while S3 offers scalable and flexible storage for various data types. Whether for immediate analysis or long-term storage and retrieval, this combination maximizes the value of data in SAP. This dual capability ensures that organizations can address the full range of data needs, from real-time insights to large-scale archiving, while maintaining the flexibility and performance needed to stay competitive in today’s data-driven landscape.
Amazon Redshift: A high-performance data warehouse
Amazon Redshift is a fully managed data warehouse service designed for large-scale data analytics. It allows complex queries on structured data and provides high-speed performance through its columnar storage and massively parallel processing (MPP) architecture.
How Xtract Universal works with Amazon Redshift
Structured data loading:
- Xtract components simplify loading structured and multidimensional data from SAP into Redshift, supporting robust analytics and rapid query performance for large datasets.
- SAP data can be efficiently extracted into Redshift to support detailed operational reporting and centralized data warehousing, including financial records, sales data from InfoCubes, and organizational hierarchies.
- Redshift’s columnar storage and high-performance capabilities enhance in-depth analysis and complex queries on SAP data.
Integration with BI tools:
- Amazon Redshift’s tight integration with business intelligence tools allows seamless data visualization and reporting once the data is transferred. This is particularly advantageous for real-time analytics and dashboarding.
Data transformation:
- Before data reaches Redshift, Xtract components can ensure that the data types are properly mapped from SAP ABAP types to Redshift data.
Batch and real-time loading:
- Redshift supports both batch processing and near real-time data loading, enhanced by Xtract Universal.
Ideal use cases with Amazon Redshift:
- High-performance analytics: Large volumes of structured data requiring rapid query responses.
- Operational reporting: Aggregated and detailed reporting based on SAP operational data.
- Data warehousing: Centralized storage and analysis of SAP and non-SAP data.
Amazon S3: Scalable object storage
Amazon S3 is a scalable object storage service optimized for large volumes of data. It offers durability, high availability, and cost-effectiveness, especially for unstructured and semi-structured data.
How Xtract Universal works with Amazon S3
Flexible data storage:
- Xtract components can transfer large-scale data from SAP systems into S3, supporting the creation of a centralized data lake for long-term retention and future processing.
- S3 can store a variety of data forms, from hierarchical organizational structures and custom data objects to multidimensional data from SAP BW and incrementally captured data, accommodating different data models and requirements.
- The advantage of S3’s scalable and economical storage solutions is to manage extensive volumes of SAP data efficiently, ensuring that the data remains accessible for batch processing or analysis on demand.
Cost-effective storage:
For data that doesn’t require the low-latency access that Redshift provides, S3 offers a cost-effective storage solution, suitable for backups, logs, or historical data that is infrequently accessed.
Integration and data movement:
S3 serves as an excellent staging area for ETL (Extract, Transform, Load) processes. Xtract can stage data in S3, which can then be transformed and moved to other destinations, including Redshift, using AWS services like Glue or Lambda.
Ideal use cases with Amazon S3:
- Big data storage: Storing vast amounts of SAP data for batch processing and big data analytics.
- Data archiving: Long-term storage of SAP reports, logs, and historical data.
- Staging area for ETL: Intermediate storage before data is transformed and moved to other databases or warehouses.
Key differences in data handling
When deciding between Amazon Redshift and Amazon S3 for SAP data, it’s important to understand their key differences. These differences include how each service handles data structure and accessibility, as well as cost and performance considerations.
Data structure and accessibility:
- Amazon Redshift is optimized for structured data and immediate retrieval, making it ideal for scenarios where data needs to be analyzed right after loading.
- Amazon S3 can handle both structured and unstructured data, but it is not designed for direct querying. Instead, it is used for storing raw data that may later be processed and queried after further transformation.
Cost and performance:
- Amazon Redshift generally involves higher costs due to its performance capabilities, suitable for environments where query speed and performance are critical. The data load performance may be a bit slower due to the data validation taking place during the process.
- Amazon S3 offers more economical storage, ideal for data that is accessed less frequently or used for backup and archival purposes. The data load process is very fast.
Data transformation and management using Xtract Universal with AWS Redshift
When integrating SAP data with Amazon Redshift or S3 using Xtract Universal, understanding the data transformation and management requirements is crucial. This section outlines the necessary preparation steps and configuration options to ensure optimal performance and compatibility.
Xtract Universal with Redshift requires pre-structured and sometimes transformed data for optimal compatibility with Redshift’s columnar storage. The graphic below illustrates the actions available for managing data during the load process into Redshift.
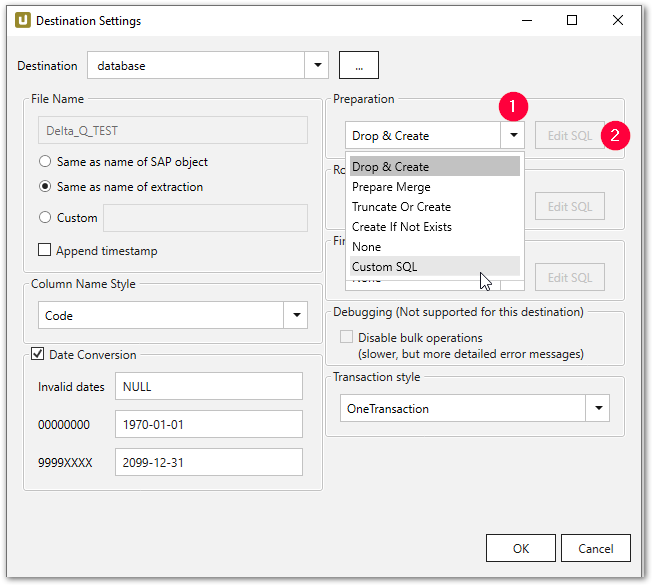
- Drop & Create: Deletes the existing table and creates a new one.
- Truncate Or Create: Empties the table if it exists or creates a new one.
- Create If Not Exists: Creates the table only if it doesn’t already exist.
- Prepare Merge: Sets up for merging data, including creating staging tables.
- None: No changes are made; data is loaded into the existing table.
Data transformation and management using Xtract Universal with Amazon S3
Xtract Universal with S3 can handle data in its raw form, making it versatile for various types of data that may not need immediate transformation. When setting up the S3 destination in the Xtract tool, selecting the appropriate Parquet compatibility mode can significantly impact the data’s usability and performance in downstream applications. Here’s how to decide:
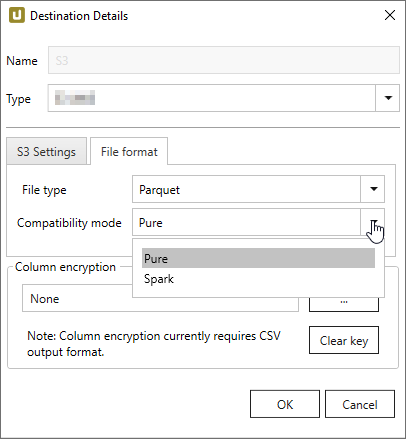
- Pure Mode: If a versatile format that can be consumed by various systems without any specific optimization is needed.
- Spark Mode: If the primary goal is to leverage Apache Spark for extensive data processing and analytics.
- BigQuery Mode: If planned to use Google BigQuery for fast and scalable data querying.
Conclusion
Choosing between Amazon Redshift and Amazon S3 as a destination for SAP data extraction depends on an organization’s requirements and specific needs.
Amazon Redshift is ideal for scenarios that require high-speed analysis of structured data, with robust query capabilities to support detailed operational reporting and business intelligence.
Amazon S3 excels when scalable, cost-effective storage is required for a variety of data types, especially for archiving or as part of a broader ETL process or data lake strategy.
With Xtract Universal and its components, seamless integration of SAP data into either Amazon Redshift or S3 is possible, giving organizations the flexibility to effectively manage and analyze their data regardless of its destination.
Ready to integrate your SAP data?
Are you planning an SAP integration project with Amazon Redshift or Amazon S3 and looking for a suitable interface solution? We are happy to assist with your questions or provide a non-binding consultation.