Effiziente SAP-Datenintegration mit Amazon Redshift & Amazon S3
Im Bereich des Cloud-Datenmanagements bietet Amazon Web Services (AWS) eine Vielzahl von Storage- und Analyselösungen. Zwei der wichtigsten Services in diesem Bereich sind Amazon Redshift und Amazon S3. Für Unternehmen, die SAP-Datenextraktionstools (z. B. die Xtract-Tool-Suite von Theobald Software) nutzen, ist es entscheidend, die Unterschiede zwischen diesen beiden AWS-Diensten zu verstehen. Dieser Blogbeitrag zeigt, wie Xtract Universal mit Amazon Redshift und S3 integriert wird, um die richtige Lösung für Ihre SAP-Datenanforderungen zu finden.
Überblick:
- Xtract Universal Extraktionstypen
- Über Amazon Redshift: Das leistungsstarke Data Warehouse
- Über Amazon S3: Der skalierbare Objektspeicher
- Unterschiede in der Datenverarbeitung zwischen AWS Redshift und S3
- Datentransformation und -management mit Xtract Universal und AWS Redshift
- Datentransformation und -management mit Xtract Universal und Amazon S3
Datentransformation und -management mit Xtract Universal und Amazon S3
Xtract Universal unterstützt die folgenden zehn Extraktionstypen, um verschiedene SAP-Datenextraktionsanforderungen zu erfüllen. Hier ist eine Übersicht der Komponenten, die für die Extraktion von Daten aus SAP-Systemen in eines der beiden Amazon-Ziele verfügbar sind:
- BAPI greift auf BAPIs und RFC-Funktionsmodule zu
- BW Cube extrahiert Daten aus SAP BW InfoCubes und BEx Queries
- BW Hierarchy extrahiert Hierarchien aus einem SAP BW / BI-System
- DeltaQ extrahiert Datenquellen (OLTP) und Extraktoren aus ERP- und ECC-Systemen
- ODP extrahiert Daten über das SAP Operational Data Provisioning (ODP)-Framework für Quellobjekte wie CDS Views, HANA Views, BW/4HANA-Objekte, BW-Extraktoren, SLT-Server
- Open Hub Services (OHS) extrahieren InfoSpokes und OHS-Ziele
- Query extrahiert ERP-Abfragen (SQ01-Abfragen)
- Report extrahiert ABAP-Berichte (T-Codes)
- Table extrahiert Daten aus SAP-Tabellen und -Sichten; ermöglicht das Verbinden mehrerer Tabellen auf SAP-Seite
- TableCDC extrahiert Änderungsdaten aus SAP-Tabellen
Durch den Einsatz der verschiedenen Komponenten von Xtract Universal können SAP-Daten effizient in Amazon Redshift und S3 integriert werden, wobei die Stärken jeder Plattform optimal genutzt werden. Redshift bietet leistungsstarke Analysen und schnelle Abfragemöglichkeiten, während S3 eine skalierbare und flexible Speicherung für verschiedene Datentypen bietet. Ob für die sofortige Analyse oder die langfristige Speicherung und Abfrage, diese Kombination maximiert den Wert der SAP-Daten. Diese doppelte Funktionalität stellt sicher, dass Unternehmen ihren gesamten Datenbedarf abdecken können – von Echtzeiteinblicken bis hin zur Archivierung in großem Maßstab – und dabei die Flexibilität und Leistung beibehalten, die in der heutigen datengetriebenen Landschaft erforderlich sind.
Amazon Redshift: Ein leistungsstarkes Data Warehouse
Amazon Redshift ist ein vollständig verwalteter Data Warehouse Service, der für groß angelegte Datenanalysen konzipiert ist. Er ermöglicht komplexe Abfragen aus strukturierten Daten und bietet durch seine Spaltenspeicherung und die Massively Parallel Processing (MPP)-Architektur eine hohe Geschwindigkeit.
Wie Xtract Universal mit Amazon Redshift funktioniert
Strukturierte Datenladevorgänge:
- Xtract-Komponenten vereinfachen das Laden strukturierter und multidimensionaler Daten aus SAP in Redshift und unterstützen robuste Analysen und schnelle Abfragen großer Datenmengen.
- SAP-Daten können effizient in Redshift extrahiert werden, um detaillierte operative Berichte und zentralisierte Data Warehousing zu unterstützen, einschließlich Finanzaufzeichnungen, Verkaufsdaten aus InfoCubes und organisatorischen Hierarchien.
- Die Spaltenspeicherung und die hohe Leistungsfähigkeit von Redshift verbessern die tiefgehende Analyse und komplexe Abfragen von SAP-Daten.
Integration mit BI-Tools:
- Die enge Integration von Amazon Redshift mit Business Intelligence-Tools ermöglicht eine nahtlose Datenvisualisierung und Berichterstellung, sobald die Daten übertragen wurden. Dies ist besonders vorteilhaft für Echtzeitanalysen und Dashboards.
Datenumwandlung:
- Bevor Daten Redshift erreichen, können Xtract-Komponenten sicherstellen, dass die Datentypen korrekt von SAP ABAP-Typen zu Redshift-Daten zugeordnet werden.
Batch- und Echtzeit-Ladevorgänge:
- Redshift unterstützt sowohl Batch-Verarbeitung als auch das Laden von Daten nahezu in Echtzeit, was durch Xtract Universal zusätzlich unterstützt wird.
Ideale Anwendungsfälle mit Amazon Redshift:
- Hochleistungsanalysen: Große Mengen strukturierter Daten, die schnelle Abfrageantworten erfordern.
- Operatives Reporting: Aggregierte und detaillierte Berichte auf Basis von SAP-Daten.
- Data Warehousing: Zentrale Speicherung und Analyse von SAP- und Nicht-SAP-Daten.
Amazon S3: Skalierbarer Objektspeicher
Amazon S3 ist ein skalierbarer Objektspeicher, der für große Datenmengen optimiert ist. Er bietet Beständigkeit, Hochverfügbarkeit und Kosteneffizienz, insbesondere für unstrukturierte und semistrukturierte Daten.
Wie Xtract Universal mit Amazon S3 funktioniert
Flexibler Datenspeicher:
- Xtract Universal-Komponenten können großvolumige Daten aus SAP-Systemen in S3 übertragen und so die Erstellung eines zentralisierten Data Lake für langfristige Speicherung und zukünftige Verarbeitung unterstützen.
- S3 kann verschiedene Datenformen speichern, von hierarchischen Organisationsstrukturen und benutzerdefinierten Datenobjekten bis hin zu multidimensionalen Daten aus SAP BW und inkrementell erfassten Daten, um unterschiedliche Datenmodelle und Anforderungen zu erfüllen.
- Der Vorteil der skalierbaren und kostengünstigen Speicherlösungen von S3 besteht darin, umfangreiche Mengen von SAP-Daten effizient zu verwalten und sicherzustellen, dass die Daten für Batch-Verarbeitung oder bedarfsorientierte Analysen zugänglich bleiben.
Kostengünstiger Speicher:
Für Daten, die nicht den niedrigen Latenzzugriff erfordern, den Redshift bietet, stellt S3 eine kostengünstige Speicherlösung dar, die sich für Backups, Protokolle oder historische Daten eignet, die selten abgerufen werden.
Integration und Datenübermittlung:
S3 dient als hervorragender Zwischenspeicher für ETL-Prozesse (Extract, Transform, Load). Xtract Universal kann Daten in S3 zwischenspeichern, die dann mithilfe von AWS-Diensten wie Glue oder Lambda transformiert und an andere Ziele, einschließlich Redshift, weitergeleitet werden.
Ideale Anwendungsfälle mit Amazon S3:
- Big Data Speicherung: Speicherung großer Mengen von SAP-Daten für Batch-Verarbeitung und Big Data-Analysen.
- Datenarchivierung: Langfristige Speicherung von SAP-Berichten, Protokollen und historischen Daten.
- Zwischenablage für ETL: Zwischenspeicherung vor der Datenumwandlung und Weiterleitung an andere Datenbanken oder Data Warehouses.
Wichtige Unterschiede in der Datenverarbeitung
Bei der Entscheidung zwischen Amazon Redshift und Amazon S3 für SAP-Daten ist es wichtig, die wesentlichen Unterschiede zu verstehen. Diese umfassen, wie jeder Dienst Datenstruktur und -zugänglichkeit handhabt, sowie Kosten- und Leistungsüberlegungen.
Datenstruktur und -zugänglichkeit
- Amazon Redshift ist für strukturierte Daten und sofortigen Abruf optimiert, was es ideal für Szenarien macht, in denen Daten sofort nach dem Laden analysiert werden müssen.
- Amazon S3 kann sowohl strukturierte als auch unstrukturierte Daten verarbeiten, ist aber nicht für direkte Abfragen konzipiert. Stattdessen dient es der Speicherung von Rohdaten, die später nach weiterer Umwandlung verarbeitet und abgefragt werden können.
Kosten und Leistung:
- Amazon Redshift ist aufgrund seiner Leistungsfähigkeit in der Regel mit höheren Kosten verbunden und eignet sich für Umgebungen, in denen Abfragegeschwindigkeit und Leistung entscheidend sind. Die Datenladeleistung kann aufgrund der während des Prozesses durchgeführten Datenvalidierung etwas langsamer sein.
- Amazon S3 bietet kostengünstigeren Speicher, ideal für Daten, die weniger häufig abgerufen werden oder für Backup- und Archivierungszwecke verwendet werden. Der Datenladeprozess ist sehr schnell.
Datentransformation und -management mit Xtract Universal und AWS Redshift
Bei der Integration von SAP-Daten mit Amazon Redshift oder S3 mithilfe von Xtract Universal ist es entscheidend, die Anforderungen an Datenumwandlung und -management zu verstehen. Dieser Abschnitt beschreibt die notwendigen Vorbereitungsschritte und Konfigurationsoptionen, um optimale Leistung und Kompatibilität sicherzustellen.
Xtract Universal mit Redshift erfordert vorstrukturierte und manchmal transformierte Daten, um eine optimale Kompatibilität mit der Spaltenspeicherung von Redshift zu gewährleisten. Die folgende Grafik zeigt die verfügbaren Aktionen zur Verwaltung von Daten während des Ladeprozesses in Redshift:
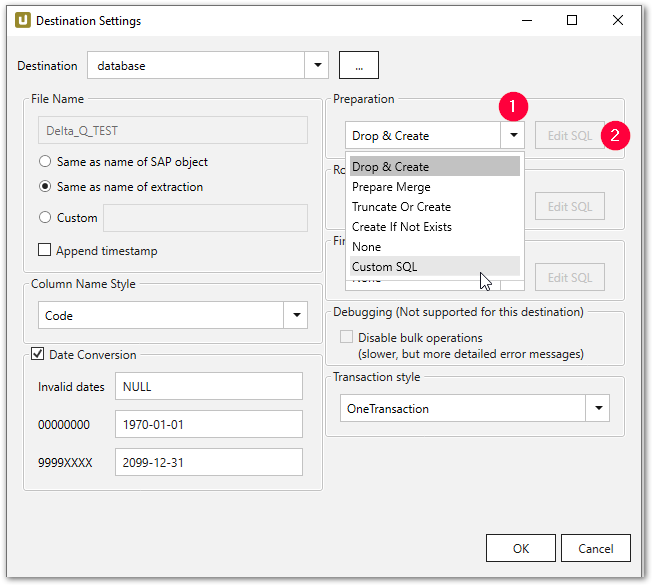
- Drop & Create: Löscht die vorhandene Tabelle und erstellt eine neue.
- Truncate Or Create: Leert die Tabelle, falls sie existiert, oder erstellt eine neue.
- Create If Not Exists: Erstellt die Tabelle nur, wenn sie noch nicht existiert.
- Prepare Merge: Bereitet das Zusammenführen von Daten vor, einschließlich der Erstellung von Staging-Tabellen.
- None: Es werden keine Änderungen vorgenommen; die Daten werden in die vorhandene Tabelle geladen.
Datenumwandlung und -management mit Xtract Universal und Amazon S3
Xtract Universal mit S3 kann Daten in ihrer Rohform verarbeiten, was es vielseitig für verschiedene Datentypen macht, die möglicherweise keine sofortige Transformation erfordern. Bei der Einrichtung des S3-Ziels im Xtract-Tool kann die Auswahl des geeigneten Parquet-Kompatibilitätsmodus die Nutzbarkeit und Leistung der Daten in nachgelagerten Anwendungen erheblich beeinflussen. So treffen Sie die Entscheidung:
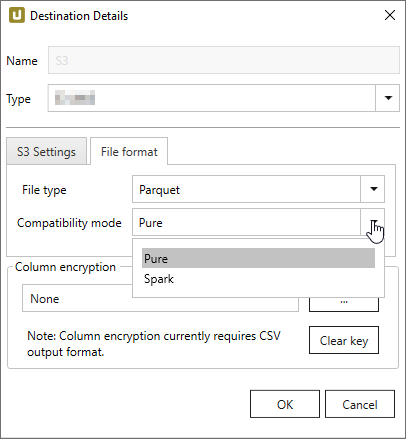
- Pure Mode: Wenn ein vielseitiges Format benötigt wird, das von verschiedenen Systemen ohne spezifische Optimierung verwendet werden kann.
- Spark Mode: Wenn das Hauptziel darin besteht, Apache Spark für umfangreiche Datenverarbeitung und Analysen zu nutzen.
- BigQuery Mode: Wenn geplant ist, Google BigQuery für schnelle und skalierbare Datenabfragen zu verwenden.
Fazit
Die Wahl zwischen Amazon Redshift und Amazon S3 als Ziel für die SAP-Datenextraktion hängt von den Anforderungen und spezifischen Bedürfnissen einer Organisation ab.
Amazon Redshift ist ideal für Szenarien, die eine schnelle Analyse strukturierter Daten erfordern, mit robusten Abfragefunktionen zur Unterstützung detaillierter operativer Berichte und Business Intelligence.
Amazon S3 hingegen eignet sich am besten, wenn ein skalierbarer, kostengünstiger Speicher für verschiedene Datentypen benötigt wird, insbesondere für Archivierungszwecke oder als Teil einer umfassenderen ETL-Prozess- oder Data Lake-Strategie.
Mit Xtract Universal und seinen Komponenten ist eine nahtlose Integration von SAP-Daten in entweder Amazon Redshift oder S3 möglich, was Organisationen die Flexibilität gibt, ihre Daten effektiv zu verwalten und zu analysieren, unabhängig von ihrem Ziel.
Bereit für die Integration Ihrer SAP-Daten?
Planen Sie ein SAP-Integrationsprojekt mit Amazon Redshift oder Amazon S3 und suchen Sie nach einer geeigneten Schnittstellenlösung? Wir helfen Ihnen gerne bei Ihren Fragen oder bieten Ihnen eine unverbindliche Beratung an. Einfach mal auf unserer Kontaktseite vorbeischauen.

Brian Smoot
Brian Smoot ist Technical Account Manager bei Theobald Software in den USA. Er ist spezialisiert auf die Integration von SAP-Daten in Anwendungen und Data Warehouses von Drittanbietern. Brian arbeitet eng mit Unternehmenskunden und Partnern zusammen, um eine nahtlose Datenintegration und -extraktion zu gewährleisten. Mit seiner umfassenden Erfahrung in der SAP-Daten- und Prozessintegration hilft er Unternehmen, ihre SAP-Daten effektiv zu nutzen.
Weitere relevante Beiträge

Microsoft Fabric & Open Mirroring: Effiziente SAP-Datenintegration ohne ODP
Unternehmen, die SAP-Daten für Analysen nutzen, stehen vor einer neuen Herausforderung: Die SAP-Note 3255746 schränkt die Nutzung des ODP-Connectors ein, wodurch viele nach Alternativen für eine effiziente und inkrementelle [...]
Von Denise Brüggemann|Veröffentlicht am: 28/04/2025|Kategorien: Neuester Beitrag, Products & Technology|-
ABAP-Programmierung im Vergleich zu Drittanbieter-SAP-Extraktoren: Welcher Ansatz passt zu Ihrer SAP-Datenstrategie?
Bei der Integration von SAP-Daten stehen vor allem zwei Ansätze im Vordergrund: ABAP-Programmierung und SAP-Extraktoren von Drittanbietern. Für Entwickler und IT-Entscheider ist die Wahl der richtigen Methode entscheidend für [...]
-
Neues Theobald Software HelpCenter: Ihre zentrale Anlaufstelle für alle Informationen
Wir bei Theobald Software wissen, wie wichtig es ist, unseren Kunden und Partnern nicht nur leistungsstarke und zuverlässige Software zu bieten, sondern auch klare und leicht zugängliche technische Informationen [...]
-
Reaktion auf SAP-Hinweis 3255746: Lösungen von Theobald Software für Xtract-Produkte
Die Aktualisierung des SAP-Hinweises 3255746 ist für unsere Kunden und Geschäftspartner verständlicherweise sehr beunruhigend. Die neue Richtlinie besagt, dass die Verwendung der RFC-Module der Operational Data Provisioning (ODP) Data [...]
-
Datenreplikation mit Change Data Capture und Operational Data Provisioning
CDC, ODP, ETL und SAP SLT – diese Anreihung von Akronymen klingt fast wie aus dem Refrain eines deutschen Hip-Hop-Songs entsprungen. Doch hinter diesen Begriffen verbirgt sich keine Musik, [...]
-
Daten im Fluss: SAP-Schnittstellen und Integration
Stellen Sie sich vor, Ihr Unternehmen ist ein riesiges Puzzle. Es besteht aus vielen einzelnen Teilen, von denen jedes eine eigene Abteilung darstellt. Jetzt müssen Sie die Teile nur [...]
-
Geringer Data Value als Problem in SAP-Systemen beheben
Der Software-Hersteller SAP zählt im Bereich der Unternehmenssoftware ohne Zweifel zu den Marktführern. Weltweit setzen Tausende Unternehmen auf die Technologie von SAP, um Geschäftsprozesse zu planen, durchzuführen und abzurechnen. Dabei entstehen riesige Datenmengen. [...]